不久前在4月中旬,关于AI大模型到底是“开源好”、还是“闭源好”这个问题,国内互联网行业中曾有过一阵论战。
当时“闭源大模型”的支持者最大的一条论据,就是历数那时候已经发布的大模型就会发现,尽管开源大模型近年来进步很快,但它们的客观性能还是普遍落后于闭源方案。由此可以证明,更能赚钱的闭源大模型才有长期成长的动力。
大模型的开源和闭源如何定义?Meta给了个好例子
但问题在于,当时可能所有人都没想到的是,就在这场论战发生不过几天时间,Meta方面就发布了他们最新的开源大模型Llama 3,并一口气将许多关键指标提升到了超过绝大多数闭源大模型的水准。从某种程度上来说,可谓是狠狠地打了“闭源支持者”的脸。

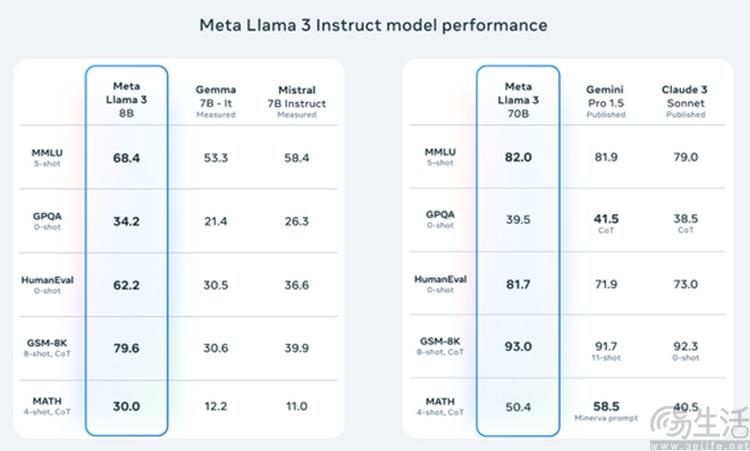
比如在公开的训练数据方面,Llama 3使用了超过15万亿的公共数据,经过两个24000GPU的集群训练而来。Meta方面虽然没有公布更进一步的训练细节,但他们有提到,Llama 3 Instruct针对对话应用进行了优化,其结合了超过1000万的人工标注数据,通过监督式微调(SFT)、拒绝采样、邻近策略优化(PPO)和直接策略优化(DPO)进行训练。
以结果来说,这就使得Llama 3的小型模型参数量略有增加(从前代的7B增加到8B)。但如此小的参数量膨胀,却换来了大得多的输入和输出矩阵,显著增强了词汇库的文本编码效率,并有望显著优化多语种混合处理时的性能。

总的来说,Llama 3的能力(特别是其中的70B版本)公认已经能够与Gemini 1.5 Pro、GPT-4等顶级闭源大模型“平起平坐”。而且它甚至还有着显著的价格优势,如果你的电脑配置确实足够高,那么本地部署Llama 3也绝不再是什么难事。而这对于此前的那些闭源大模型来说,更是难以想象的事情。
Llama 3谁都能用,但“在哪用”成了新的问题
当然,可以说Llama 3在技术上的成功绝大多数都应该归功于Meta,它并不是严格的、由开源社区“共建”的成果。但问题在于,评价一款大模型到底是开源、还是闭源,并不是看它究竟是哪家大公司贡献的代码更多、还是其他个人开发者的功劳更大。
因为大家所讨论的,究其根本还是商业模式上的差异。从这一点来说,哪怕Llama 3每一个字节都是Meta自己的成果,只要它的商业模式还是开源,就依然算是开源大模型。
当然,正因为Llama 3是一个开源的大模型,所以在商业层面对比那些闭源大模型它还有一个很关键的差异,那就是用户并不需要专门通过Meta这个“门户”,才能够使用上它。
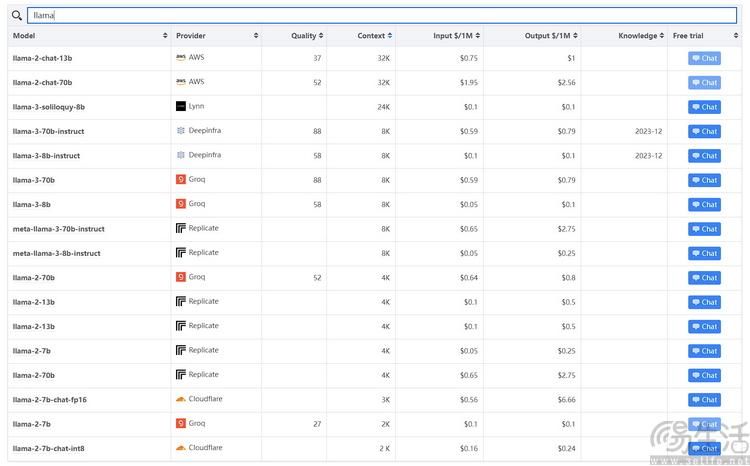
根据公开资料显示,现在至少有不低于6家不同的大模型供应商可以提供基于Llama 3的使用接口,甚至其中的一些还允许免费试用。从某种程度来说,这也可以说是开源大模型相比闭源的一大显著优势了。
小平台的风险,使得传统巨头反而成为了明智的选择
那么问题就来了,站在用户的角度上而言,这是否意味着只需要去对比不同供应商的价格,然后挑选最便宜的就好呢?

要是放在以前,这样或许没什么问题。但至少在近日的月之暗面套现风波发生后,想必不少开发者都已经对于中小供应商的长远可靠性起了疑虑。
平心而论,这也是目前一个比较无奈的情况,因为大家都知道,生成式AI毕竟是目前的大热门赛道。在这样的背景下,指望一些创业不久的平台能够“坚守初心”,不被急速膨胀的估值迷了眼,实在是有点过于考验人性了。
好在,开发者还是有些显著更靠谱的选择。比如AWS(即亚马逊云科技)就几乎是在Meta方面发布Llama3的同时,将其加入了Amazon SageMaker JumpStart服务可选模型列表中。
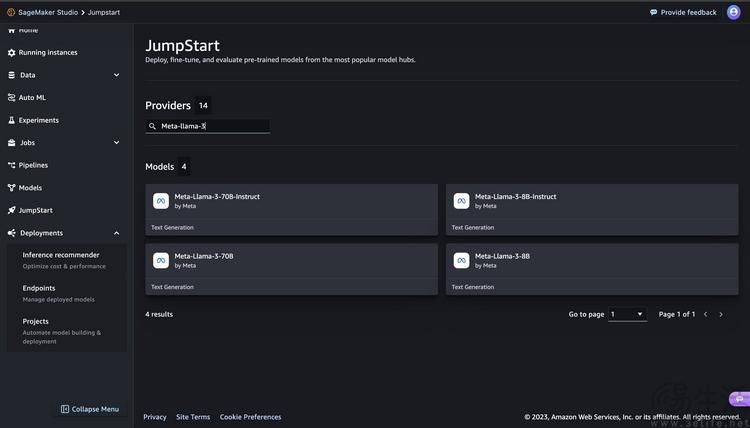
根据AWS方面公布的教程显示,通过Amazon SageMaker JumpStart,开发者可以很容易地以图形化的界面选择和部署包括Llama 3在内的多种大模型,并且在整个部署阶段都有端到端的指导,以引导开发者更简单地一步步完成整个部署、推理,甚至是完成之后的清理操作。
Llama 3很好,但AWS更看重“选择自由”
需要注意的是,与目前行业中其他能够提供Llama 3的服务商相比,AWS未必是其中单价最低的那一家。但如果考虑到基础设施的稳定性、更多区域的可用性,以及AWS过去很多年里伴随着自研算力芯片的升级、而多次主动降低价格的这一事实,那么他们的长期性价比很可能反而会更为出色。
况且不同于其他一些可能存在着“跟风”嫌疑的中小平台,AWS虽然在引入Llama 3上表现积极,但他们并没有将其视为唯一或者更突出的业务选择。
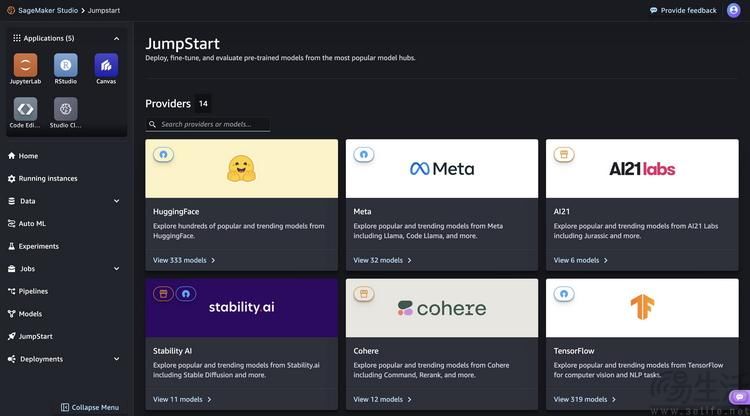
实际上,目前的AWS能够提供的大模型已经包括但不限于通过Amazon Bedrock提供,来自AI21 Labs、Amazon、Anthropic、 Cohere、Meta、Mistral AI和Stability AI的大模型,以及通过Amazon SageMaker JumpStart提供、包括Llama 3在内的各种模型。
这就不禁令我们想到去年年底举行的AWS re:Invent2023上,AWS首席执行官Adam Selipsky就曾专门提到过“模型选择自由”的重要性。

当时他表示,“不会有一个统治一切的模型,也肯定不会有一家公司能提供所有人使用的模型”。正因如此,Selipsky认为,“我们在AWS的整个历史中一直在强调这种选择的需要,这也是我们在将近一年前开始谈论我们的生成式AI战略时明确阐述的方法。这就是为什么我们继续创新,使构建和在一系列基础模型之间移动变得像API调用一样简单。”
【本文图片来自网络】
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com