


友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
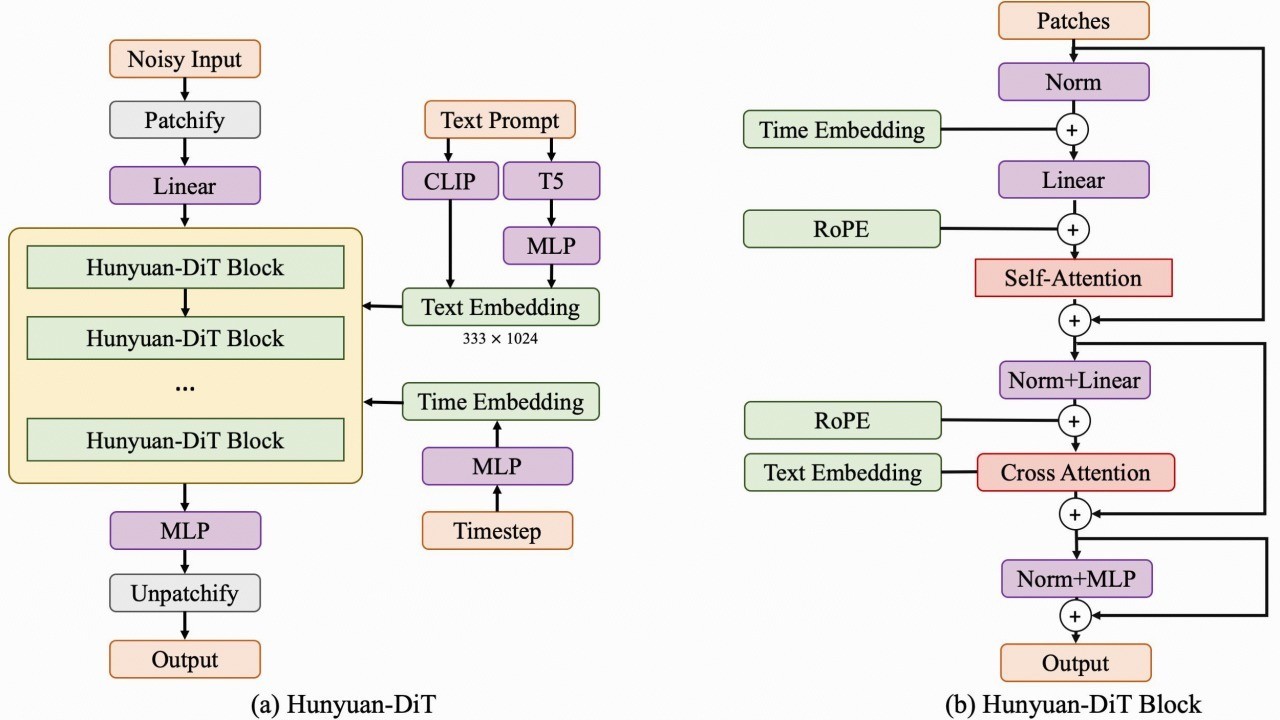
腾讯混元文生图大模型对外开源:搭载首个中英双语 DiT 架构
99
0
相关文章
近七日浏览最多
最新文章
标签云
扬尼斯
希腊
v10
wnba
恩比德
加拿大
nba
男篮
字母哥
上汽大通
房车
内存
沧海一声笑
兰博基尼
v8
跑车
蒙犽
未来战士
貂蝉
英雄
芈月
诸葛亮
打野
珍宝阁
王者荣耀
iqoo
电池容量
学生党
f1
自然吸气
空气动力学
红牛
超跑
荣耀10
摩托车
任贤齐
motor
飞天茅台
阿玛尼
龙王
体验服
brembo
道奇
科尔维特
妲己
李信
人的价值
仲夏夜之梦
杨戬
鬼谷子
皮影戏
显存
英伟达
腾讯
gpu
游戏
辅助英雄
坦克
演员
王炸
古装
收视率
电视剧
墨雨云
救赎
纯爱
周翊然
王影璐
十二封信
双双
刘贺
茅子俊
古装剧
李沁
醉梦
刘诗诗
李乃文
黄小蕾
胡先煦
悬疑大剧
倪妮
闫妮
董洁
刘敏涛
演艺生涯
莫离
复仇
王和
宫装
丞磊
白鹿演员
芒果
优酷
成毅
谭松韵
马天宇
刘奕君
国色芳华
聂远
李光复
老戏骨
哈斯朝鲁
刘烨演员
何晏
黑马
暑期档
秦昊
文淇
刘亦菲
林更新
悬疑剧
宋祖儿
陈若轩
陈鑫海
古装权谋
老顽童
感情戏
武侠剧
古力娜扎
王传君
窦靖童
宋妍霏
逆爱
抖音
柴鸡蛋
独播权
网络剧
索尼
侵权
ign
互动娱乐
知名企业
部分安卓平台
盛势
案由
网剧
著作权
拳击
颜丙燕
黑马剧
张鲁一
朱亚文
罗云熙
迪丽热巴
短剧
万茜
朱雀堂
秦俊杰
微信
安卓
代码
华为
ios
鸿蒙系统
网络浏览器
配角
孟子义
刘威
宣璐
房子斌
竖屏
爱奇艺
短视频
武侠
改编
小说
奇幻
庆余年3
三体电影
于和伟
刘慈欣
三体大史
流量
小红书与红果之争
金庸
吕颂贤
tvb
令狐冲
周润发
本王
追剧
刘浩存
王安宇
王炸剧
罪图鉴
综艺
广告
藏海传
郑晓龙
任重
曾黎
偶像剧
神话
寒武纪
张旭光
人工智能
显卡
芯片
amd
英特尔
nvidia
中国
特朗普
霍华德
黄仁勋
系列显卡
核弹ai芯片
deepseek
美国
新加坡
liming
直播
训练成本
英伟达芯片
埃隆_马斯克
钛媒体
a100
大语言模型
美ai公司
英伟达h100
字节跳动
blackwell
微软
谷歌
亚马逊
索泰
主板
反垄断
越南总理
pc
印尼
股票
埃利奥特
史蒂文斯
时代周报
应收账款
太阳能电池
郑州
苹果
富士康
rain
机器人
cpu
jonathan
初创公司
john
rtx
归母净利润
快科技
npu
处理器
研报
第一财经
ows
matebook
oled
笔记本电脑
ultra
独立显卡
海力士
三星
中企
算力
白宫
台积电
平均售价
英特尔公司
芯片问题
智能手机
追踪器
服务器
后门
比尔
网络安全
林剑
外交部
美国政府
经贸问题
机器人技术
雷军
小米手机3
su
thor
小米眼镜
小米yu7
小米adr
戴维
拜登
萨克斯
芯片出口
白宫ai
华为芯片
美国芯片
中国ai
华盛顿
唐纳德特朗普
人工智能扩散规则
小米
高通
卢伟冰
中国芯片
出口管制措施
芯片战
国产芯片
何立峰
工商界
中国贸促会
首席执行官
颠覆性
超级计算机
智能驾驶
中国车企
美媒
科技巨头
海湖庄园晚宴
纳指
美股
道指
科技股
苹果公司
标普指数
特斯拉公司
科技公司